 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
为什么批量梯度下降法(BGD)寻优路径相对比较平滑()
A.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值减小的方向
B.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值增加的方向
C.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值不变的方向
D.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值发生变化的方向
 如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值减小的方向
B.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值增加的方向
C.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值不变的方向
D.批量梯度下降法(BGD)每一次对模型参数的调整,都朝向代价函数值发生变化的方向
如搜索结果不匹配,请 联系老师 获取答案
 更多“为什么批量梯度下降法(BGD)寻优路径相对比较平滑()”相关的问题
更多“为什么批量梯度下降法(BGD)寻优路径相对比较平滑()”相关的问题
第1题
A.Adam中的学习率超参数α通常需要调整
B.Adam优化算法常用于批量梯度下降法中,而不是用于随机(小批量)梯度下降法
C.我们经常使用超参数的默认值β1=0.9,β=0.999,∈10-8
D.Adam结合了Rmsprop和动量的优点
第2题
A.随机梯度下降法最终收敛的点不一定是全局最优
B.随机梯度下降法最终收敛的点一定是全局最优
C.无论随机梯度下降法存不存在最终收敛的点,一定可以找到最优解
D.无论随机梯度下降法存不存在最终收敛的点,一定不能找到最优解
第3题
如果你训练的模型代价函数J随着迭代次数的增加,绘制出来的图如下,那么()。
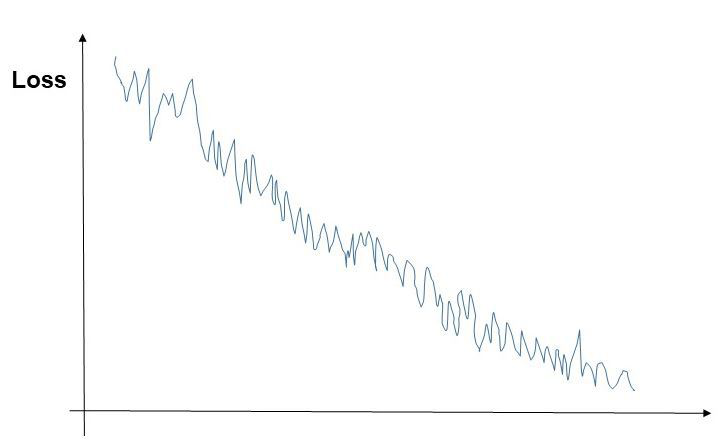
A.无论你在使用mini-batch还是批量梯度下降,看上去都是合理的
B.如果你正在使用mini-batch梯度下降,那可能有问题;而如果你在使用批量梯度下降,那是合理的
C.如果你正在使用mini-batch梯度下降,那看上去是合理的;而如果你在使用批量梯度下降,那可能有问题
D.无论你在使用mini-batch还是批量梯度下降,都可能有问题
第5题
A.交叉熵也可以作为分类预测问题的损失函数
B.在使用梯度下降时,加上冲量项会减少训练的速度,但可能会增加陷入局部极小值的可能
C.与批量梯度下降法相比,使用小批量梯度下降法可以降低训练速度,但达到全局最优解可能需要更多的迭代次数
D.神经元的激活函数选择不影响神经网络的训练过程和最终性能
第10题
A.BP神经网络的训练过程中,先进行后向传播再进行前向传播
B.通过损失函数对后向传播结果进行判定
C.通过前向传播过程对权重参数进行修正
D.训练过程中权值参数的运算量很大,一般采用梯度下降法




为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 上学吧
微信搜一搜
上学吧
上学吧
微信搜一搜
上学吧















